
Extragerea textului din imaginile (Funcţie OCR)
Scanaţi text din imagini şi afişaţi-l în Notepad (inclus cu Windows).
![]() Important
Important
- Fişierele PDF nu pot fi convertite în text.
- Conversia textului nu poate fi posibilă, în funcţie de dimensiunea imaginii selectate.
-
Afişaţi imaginea pe care doriţi să o convertiţi în text.
-
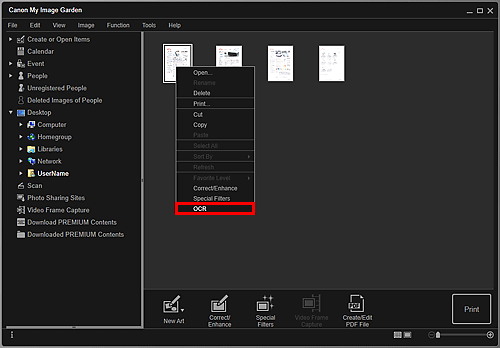
Faceţi clic dreapta pe imaginea pe care doriţi să o convertiţi în text, apoi faceţi clic pe OCR din meniul afişat.
Notepad (inclus cu Windows) porneşte şi apare textul editabil.
 Notă
Notă- Numai textul scris în limbile care pot fi selectate în fila Setări avansate (Advanced Settings) a casetei de dialog Preferinţe (Preferences) poate fi extras în Notepad (inclus în Windows). Faceţi clic pe Setări... (Settings...) din fila Setări avansate (Advanced Settings) şi specificaţi limba în conformitate cu limba documentului ce urmează să fie scanat.
Când scanaţi mai multe documente, puteţi colecta textul extras într-un singur fişier. -
Textul afişat în Notepad (inclus cu Windows) este numai pentru ghidare. Este posibil ca textul din imaginea următoarelor tipuri de documente să nu fie detectat corect.
- Documente care conţin text cu dimensiunea fonturilor în afara intervalului cuprins între 8 puncte şi 40 de puncte (la 300 dpi)
- Documente înclinate
- Documente plasate răsturnate pe verticală sau documente cu text în orientare greşită (caractere rotite)
- Documente care conţin fonturi speciale, efecte, italice sau text scris de mână
- Documente cu spaţiere prin linii înguste
- Documente cu culori în fundalul textului
- Documente care conţin mai multe limbi
- Numai textul scris în limbile care pot fi selectate în fila Setări avansate (Advanced Settings) a casetei de dialog Preferinţe (Preferences) poate fi extras în Notepad (inclus în Windows). Faceţi clic pe Setări... (Settings...) din fila Setări avansate (Advanced Settings) şi specificaţi limba în conformitate cu limba documentului ce urmează să fie scanat.
